RL Widens the ChatGPT Moat
Reinforcement Learning creates an effective defensive strategy for OpenAI and Microsoft.

In this blog, I will review the process of using Reinforcement Learning (RL) to create and improve a large-language model such as ChatGPT. I will then show how OpenAI and Microsoft can use RL to prevent competitors from competing against them in the generative AI market. I will then suggest strategies for new startups to attack the fortress. First, let’s review what we mean by a “moat” that keeps attackers from reaching the ChatGPT castle.
Background on Porter’s Five Forces Model
In 1979 Michael Porter published his seminal paper on analyzing an industry’s competitive nature. We now refer to this process as Porter’s Five Forces Analysis. We can use the diagram below to visualize a set of pressure points in any given market.

OpenAI charges a modest $20/month for premium access to ChatGPT. There is also a free version with over 100M users. OpenAI is using these users as a method to get feedback and make their model better.
When we look at ChatGPT objectively, there is really no other publically available tool that comes close to its capabilities. Although the user interface is primitive, the quality of the generated text is stunning compared to its rivals. This is the only model that is as general and has so many different uses.
So right now, we can only put OpenAI in the generative AI circle above. But this will change, and we will understand why Microsoft invested $10B in OpenAI.
For this analysis, we will ignore the Bargaining Power of Buyers since there is no competition. The Bargaining Power of Suppliers is the NIVIDA GPU hardware within Microsoft Azure and the software developers within OpenAI. These can’t be ignored in the long run, but for now, there is enough money to purchase both the hardware and pay the OpenAI developers. That leaves one force we need to consider: Threats of New Entrants. There are Threats of Substitutes for ChatGPT, such as using a search engine or reading books to find information. None of these options are appealing.
Threats of New Entrants
Looking at the diagram above, the top force is called the Threat of New Entrants. It consists of the other big tech companies that are already deeply vested in the area of large language models. This includes:
- Google — who have knowledge about search and feedback to build new models
- Amazon — has large teams of people working on machine learning to promote their cloud services to train large-language models
- Meta — where Facebook gathers around 50K facts about users that can be used to make detailed predictions of what ads they might click on
- HuggingFace — makes it easy for developers to access 100K models and fine-tune them using quick and easy Spaces applications.
All these companies have spent substantial time and money building large language models in their research areas. But they have yet to launch a product with the scope of ChatGPT.
OpenAI has a considerable lead. OpenAI first published its GPT paper on June 11th, 2018. That was followed up on Feb. 14th, 2019, with GPT-2, which had 1.5 billion parameters. This was followed by the ground-breaking GPT-3 on June 11th, 2020, which soared to an incredible 175 billion parameters. These results were impressive because the quality of text that GPT-3 generated was amazing. But OpenAI did not slow down. They added models that fine-tuned the base GPT-3 model with better instructional intent detection and also integrated another model trained on software called Codex.
Whenever a user gives a thumbs up or thumbs down, there is more data for OpenAI’s models to improve. After all this work, they applied another software layer called Reinforcement Learning with Human Feedback or RLHF. RLHF is still being used today for those 100 million users.
Three Barriers To Entry for Cognitive Assistants
Here are the three main factors that keep new entrants from joining the fray of completion against ChatGPT.
- The AI Talent — Do you have staff that has a deep appreciation for NLP and large language models? Do they have a strong understanding of the knowledge representation of your organization's data? Can your organization hire and retain this talent in a red-hot industry?
- The Training Hardware Costs — Does your organization have access to thousands of GPUs/TPUs/IPUs or HBUs to train and fine-tune large-language models?
- The Feedback — Do you have hundreds of thousands of users that are willing to give you feedback? OpenAI has over 100 million users today, and this number is expected to grow as they refine their models with this feedback.
There are also other factors, such as the narrowness of your audience, the confidentiality of the data in the prompts, the privacy of the users, risks of generating harmful content, legal and copyright concerns, and regulatory concerns. All these factors could either accelerate or prevent new entrants to the generative AI marketplace.
Apply Some Systems Thinking
When we apply the principles of Systems Thinking to this problem, we see a Causal Loop Diagram (CLD) with a positive reinforcement cycle. It looks like the following:
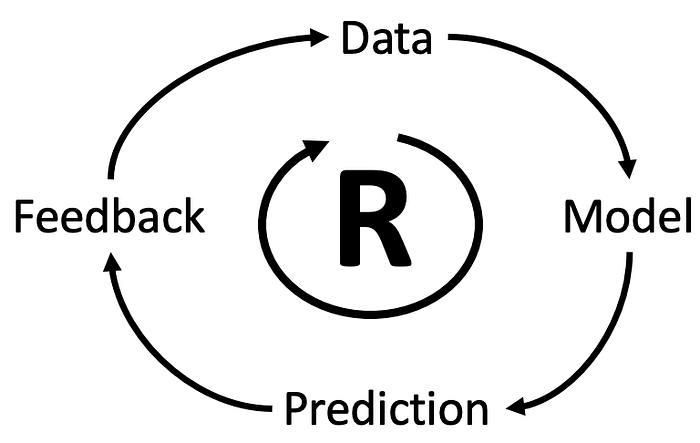
This small CLD can be explained by describing the relationships:
- Data to Model — we use data to build machine learning modes.
- Model to Prediction — we use machine learning models to make predictions about the future based on prior knowledge..
- Predictions Enable Feedback — once we can make reasonably good predictions, humans will give us feedback.
- Feedback is Data — we can use feedback as new data to improve our models.
When we see these types of positive reinforcing forces, we are reminded of the network effect that tends to keep competition out of these markets.
You can find out more about the role of Systems Thinking from by blogs on The God Graph and Systems Thinking for Knowledge Management.
The AI Flywheel With Human Feedback
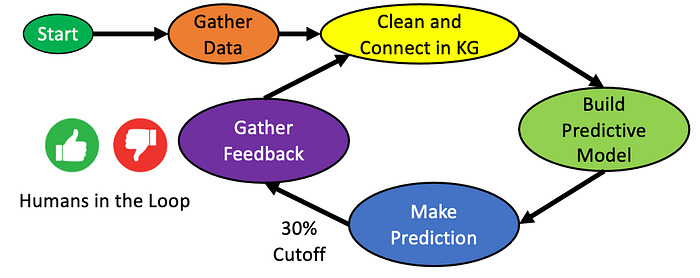
The figure above is the classic “AI Flywheel” that describes how organizations gather data, build predictive models, make predictions, and use human feedback to gather more data to make better predictions. I use this model in almost every KR and AI course I teach because it is fundamental to understanding how companies will use feedback to create new cognitive assistants.
I have modified the traditional simplified 4-component loop (data, model, predict, feedback) to include a few more details. There are two essential features of the diagram we want to focus on.
First, we want to make sure everyone understands that feedback is contextual. You not only want to know that feedback is coming from a human, but you want to know the context of this person in their environment. If this is feedback for a coding suggestion, you want to know if this is a senior or junior developer. If it is feedback on a generated letter, you want to know if the reader is a subject matter expert or a novice. Context is everything, so if you don’t use a knowledge graph, you are throwing away most of your information about the human giving you feedback.
The second is to understand that you will not gather information from humans unless you provide value to them. This means that if at least 1/3 of your suggestions are not correct, the user will disable your suggestions. They are more annoying than they are worthwhile. This is why if your predictive model is not at the 1/3 cutoff, you might need to pay users to give you feedback. This is exactly what companies like OpenAI had to do before their product launch. Once people started to use it (for free), the stream of feedback started flowing in. And with each click, the moat around ChatGPT gets wider.
Conclusion
In summary, feedback and reinforcement learning cause network effects that will keep competing out of the general ChatGPT-driven market for general cognitive assistants. If you are a small company, you may not have the resources to compete in this area. That still leaves many opportunities for small firms to build cognitive assistants that work on narrow disciplines with access to specialized data and volunteers to help them fine-tune their predictions. Finally, small startups should consider licensing systems such as OpenAI’s GPT-3 davinci models and integrate them into products.
